Lecture 05 Machine-Level Programming I: Basics
机器程序部分:关心执行程序 所执行的一串独立的指令
所谓机器程序
- 实际目标代码 -- 一串字符 -- 看不懂
- 更清晰的文本形式
- 汇编代码
机器代码在机器之上 编写的程序之下 了解机器代码 可以更好的理解我们的程序正在尝试做什么 我们的机器尝试做什么
本课程只是基于特定语言 64位 Intel指令集
History of Intel processors and architctures
Intel x86 Processors
x86是对intel的口头称谓 -- 因为第一个芯片叫 8086, 之后推出了8286(跳过了81),8386 共同点86 所以 叫 x86
x86 就是一种 指令集的语言 也有很多古怪的东西 有点像SQL一样
RISC vs. CISC -RISC: 精简指令集计算机 RISC给之前的处理器命名为CISC

386开始转换成实际可以运行Unix Linux的东西 -- 因为扩展到了32位 --删除了一些奇怪的寻址 -- 变得更加通用
Pentium 4E -- 64位 一件很聪明的事儿是 不用更换软件的情况下更换硬件 32位在64位机器上依然适用
之后遇到了功率的问题 --- 热 04年后 出现多核心

4个核心共享缓存
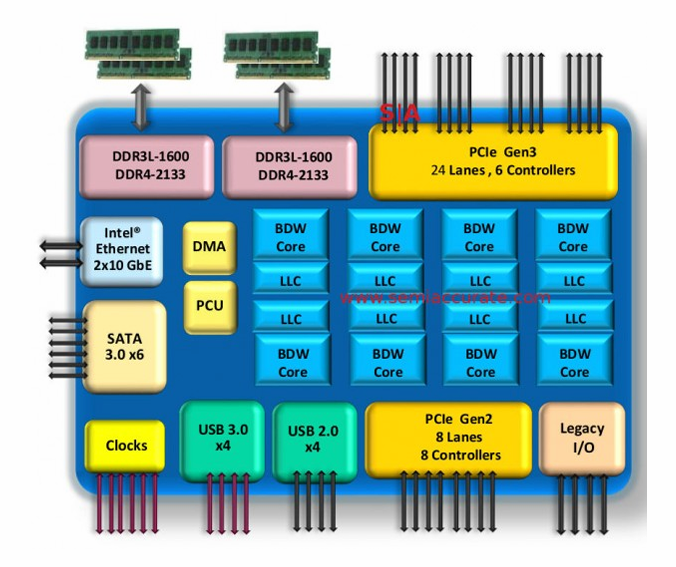
DDR是链接到主存储器的方式 -- DRAM
PCI 与外围设备的连接
x86 Clones: Advanced Micro Devices(AMD)
AMD历史性竞争对手

ARM架构 -- 比x86机器功耗低 更简单
但是这个公司没有出售处理器 只是设计处理器 -- ARM只是手机处理器中的一部分
C, assembly, machine code
Definitions
- Instruction set architecture: 指令集架构 -- 一种抽象 最好的实施指令的操作 --硬件工作者
- microarchitecture: 微结构
- Code Forms: - Machine Code - Assembly Code
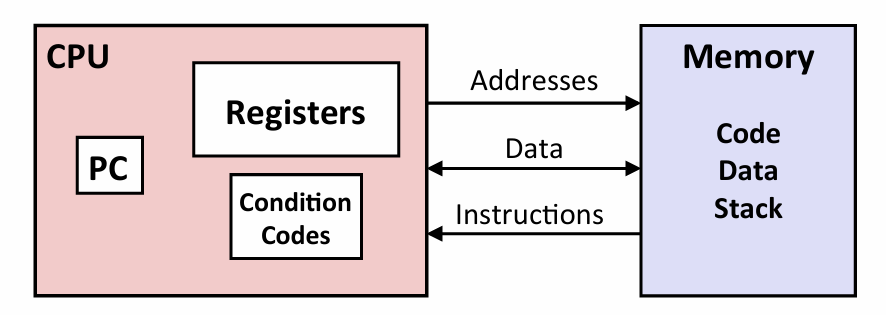
- PC
- Register file
- Condition codes -- static rigister
- Memory
Turning C into Object Code
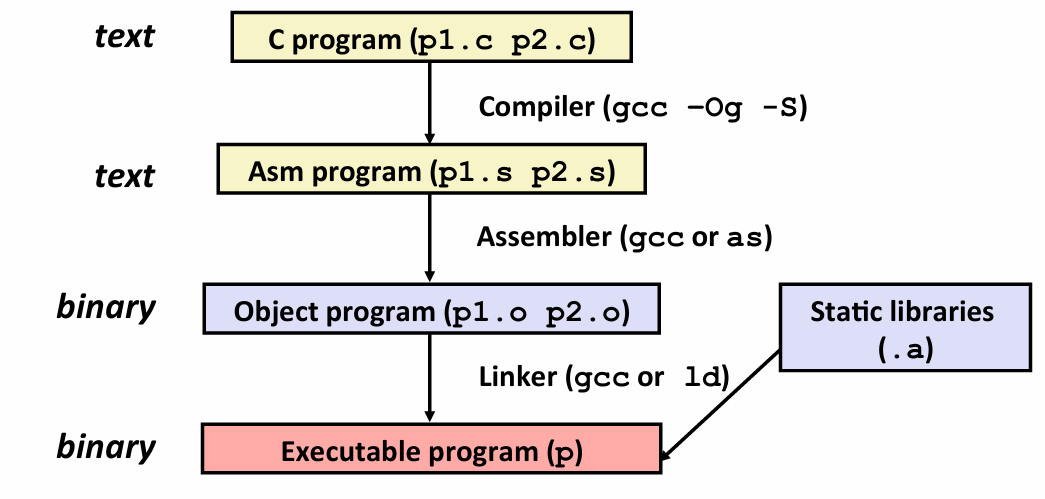
Compiling Into Assembly

%-寄存器的实际名称
pushq - 压栈 popq -- 出栈 movq--从哪到哪 call 调用 ret--返回
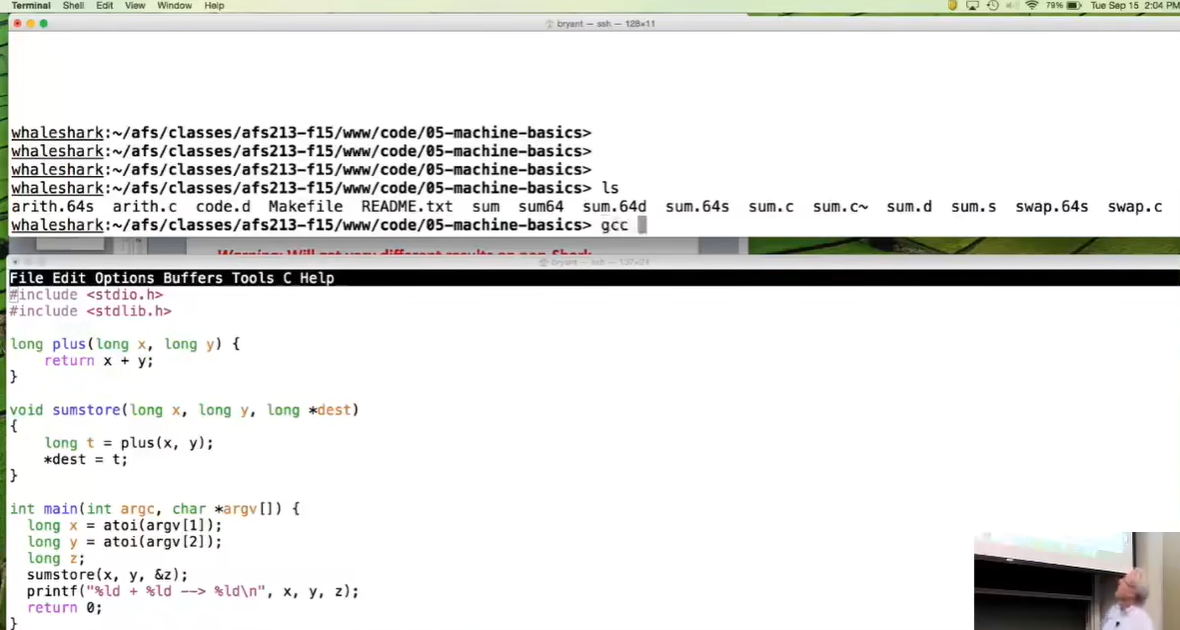
.s 文件-汇编文件 .d 反汇编文件
转变为一个汇编程序
gcc -Og -S sum.c
调用gcc时 实际上调用的不仅仅是一个程序
整个程序序列 来完成 编译的不同阶段
-S 是stop 只做第一部分 转变为汇编代码
-Og 是我希望编译器做什么样的优化的规范 如果什么也不加 就是不优化 实际上生成的代码很难看懂

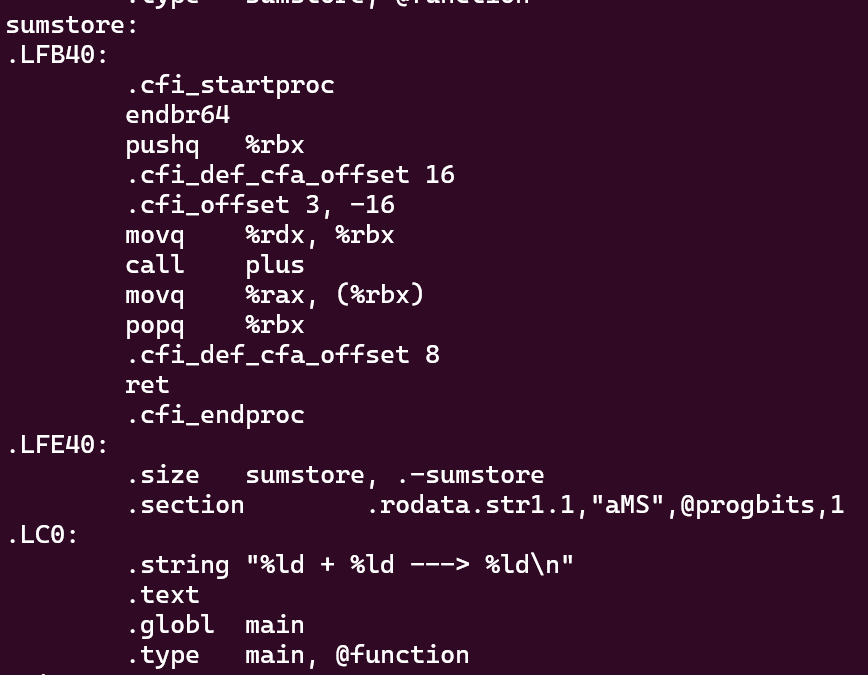
挑出来 就是上面ppt的汇编语言
但是有一些别的内容 与代码文本并不是直接相关 他们以一个.开头 指示他们是别的东西
他们与某些重要信息有关 要给debugger提供使他能够定位程序的各个部分
比如有一些再告诉编译器 这是一个全局定义的函数 -- 但在一开始的时候不用过多的去考虑
assembly characteristics: Data Types
- integer: 有许多不同类型的整数类型 size of 1, 2, 4 or 8 bytes --不区分有符号数和无符号数的存储方式 甚至地址或指针 都以数字形式存储在计算机中
- float: 一系列字节 后面lecture会讲
- array, class, structure 不存在与机器层级
Assembly Characteristic: Operations
汇编级编程的一个特点 每条指令能做的事情都非常有限 -- 基本上一条只能做一件事情

其实 就像应用视角的操作系统2024说的一样 C语言算是高级语言中的汇编语言 因为我们可以将for循环之类的东西 写成一条只干一件事儿的那种simple C的形式
Object Code

gcc -c sum.s -o sum.o
objdump能够反汇编目标文件并展示其中的机器码和汇编指令。
objdump -d sum.o
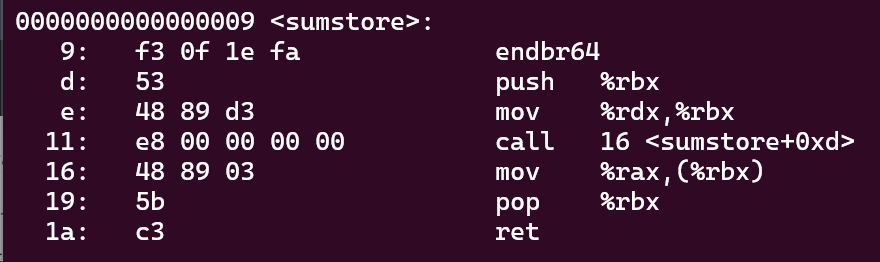
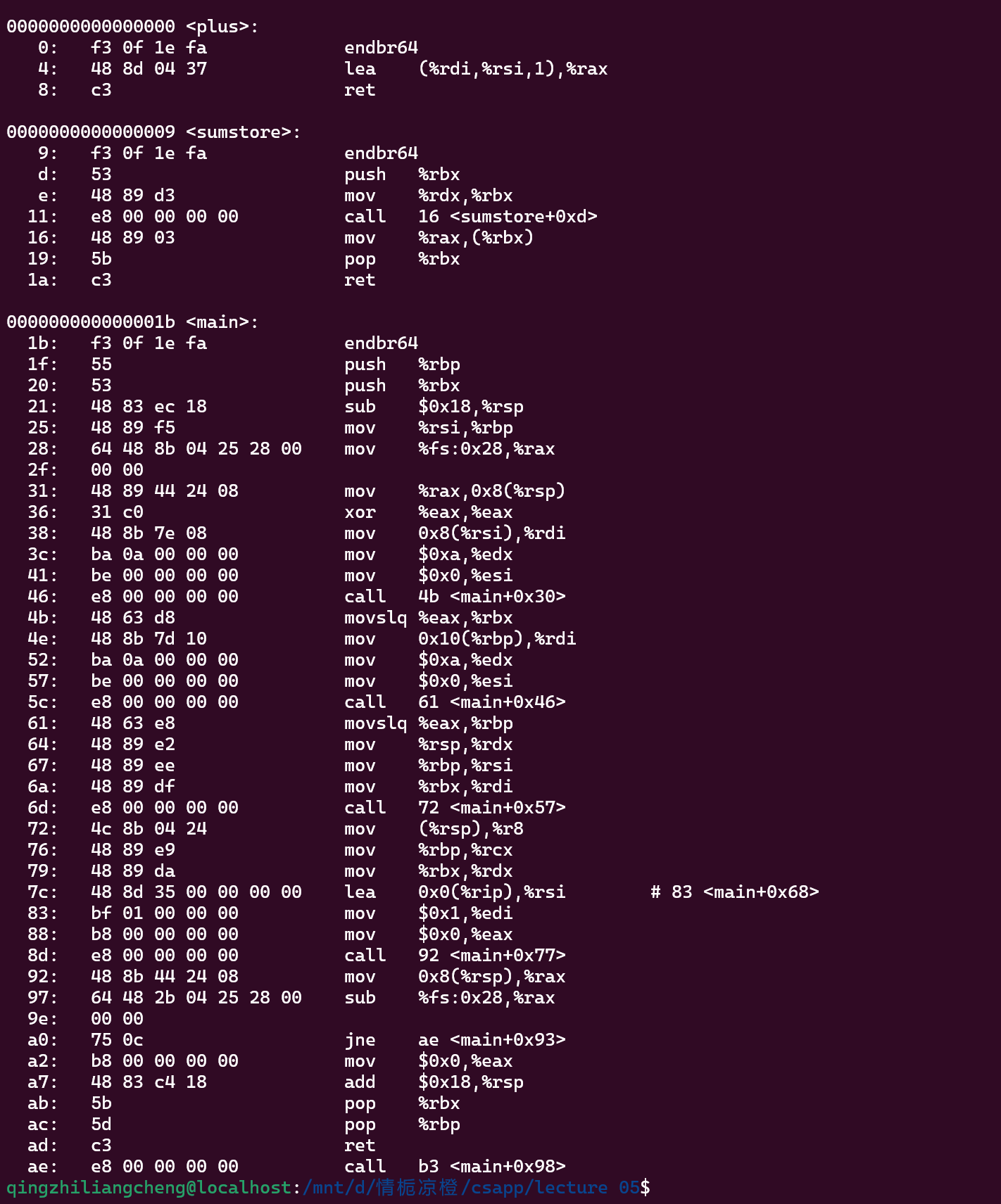
但其实从9到1a 用了17 18个byte
example

变量名--丢失了到了汇编层级

gcc -Og sum.c -o sum
objdump -d sum

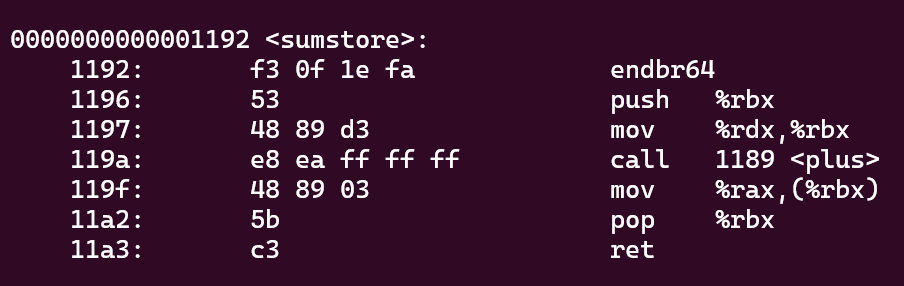
gdb也能做到
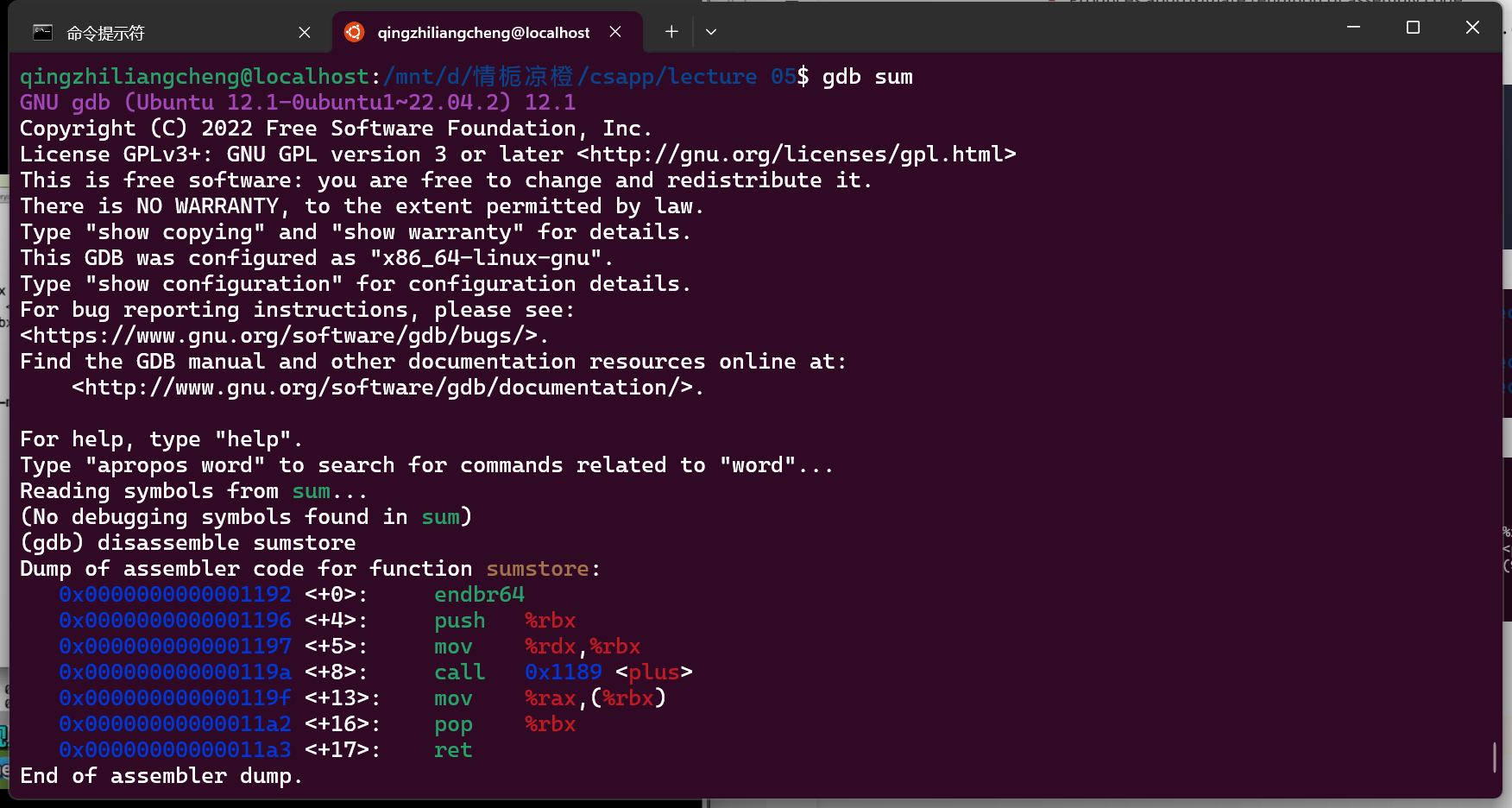
Assembly Basic: Register, operands, move

%r版本 64bit %e版本 32byte 低32byte
除此之外 还可以用低16byte 和 1byte
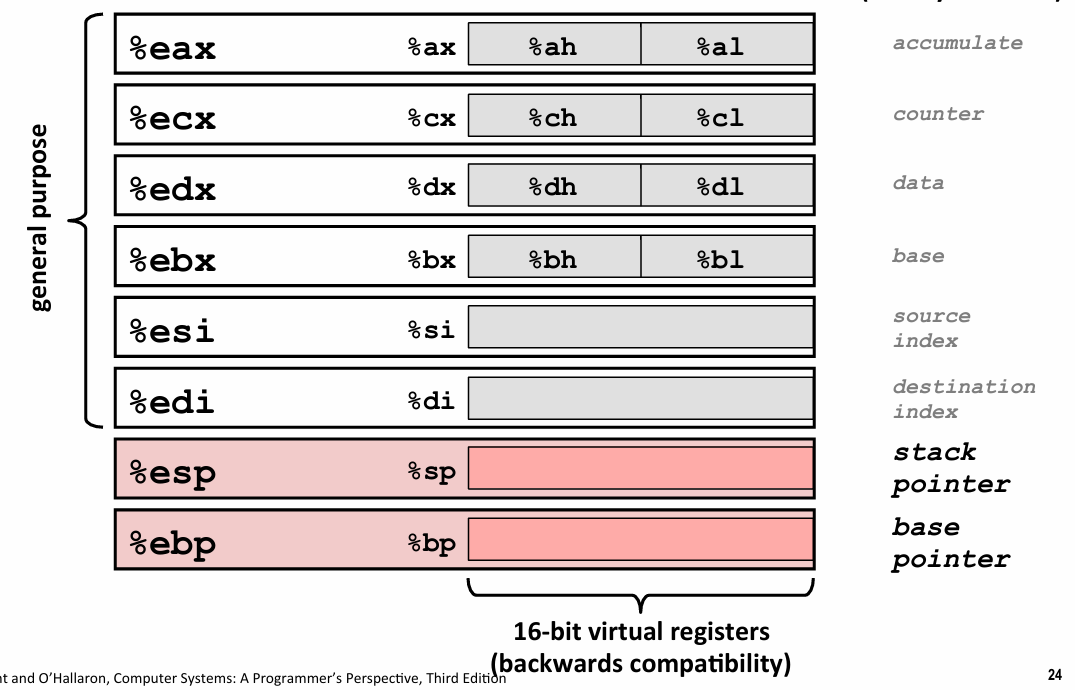
在远古时代他们每一个都有特定的用途
后来消失了
粉红色的那个Register called stack pointer
ebp是base pointer 后来不怎么用了
moving data


注意 不允许从一个内存去另一个内存

()表示地址 注意可以做一些运算 得到别的地址 这对于访问不同的数据结构非常有用
example of simple addressing modes
我写了个code 跟着ppt上的example
#include <stdio.h>
#include <stdlib.h>
void swap(long *xp, long *yp) {
long t0 = *xp;
long t1 = *yp;
*xp = t1;
*yp = t0;
}
int main(int argc, char *argv[]) {
long x = atol(argv[1]);
long y = atol(argv[2]);
printf("交换前: %ld, %ld\n", x, y);
swap(&x, &y); // 传递变量的地址
printf("交换后: %ld, %ld\n", x, y);
return 0;
}

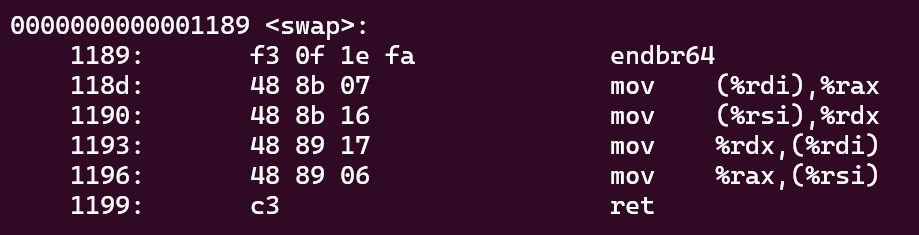
the detail
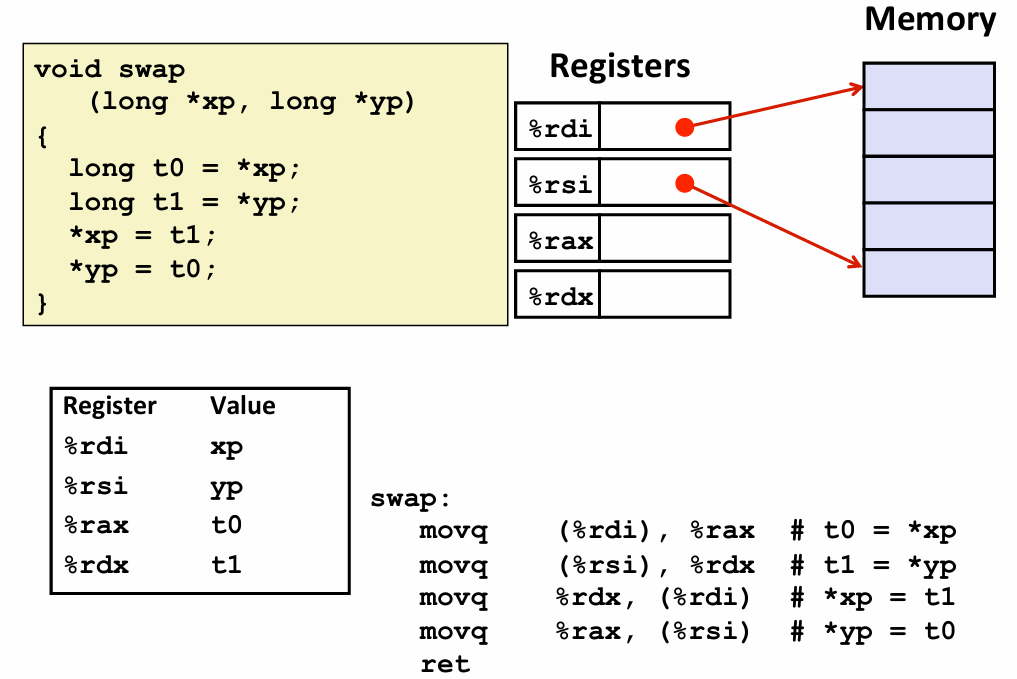
事实证明 使用x86-64 函数参数总是出现在某些特定的寄存器中
%rdi -- 第一个参数 %rsi -- 第二个参数
编译器会有自己的想法 -- 如何使用不同的寄存器来处理临时数据 -- 这就是所谓的寄存器分配算法 -- 先不关心
过程:
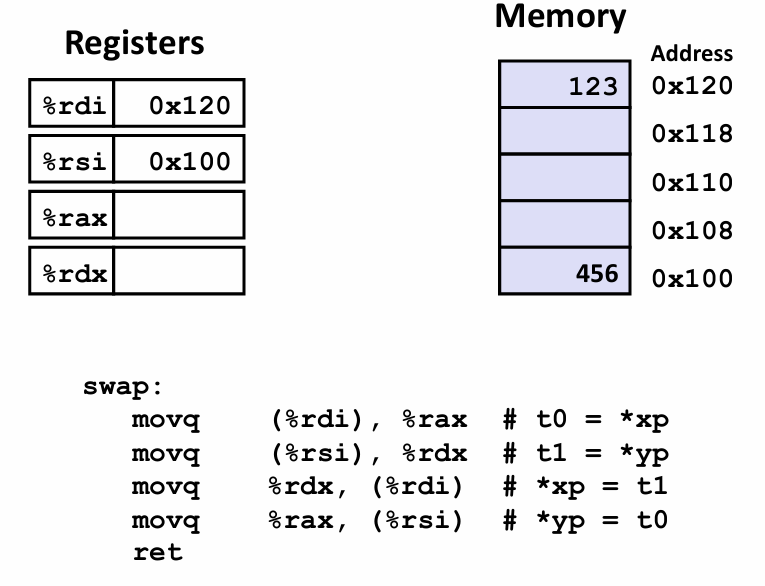
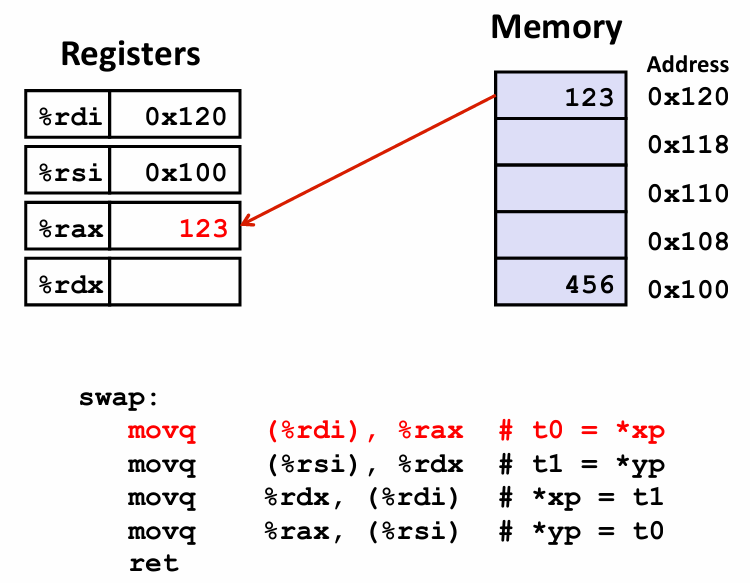
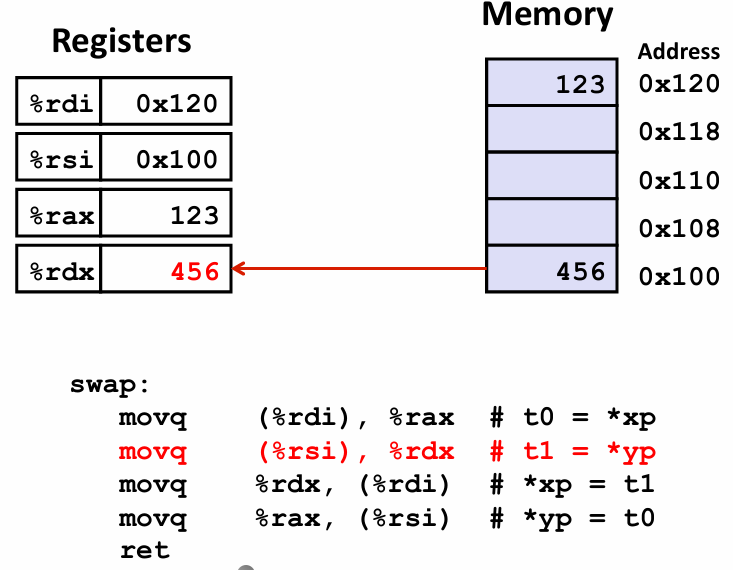
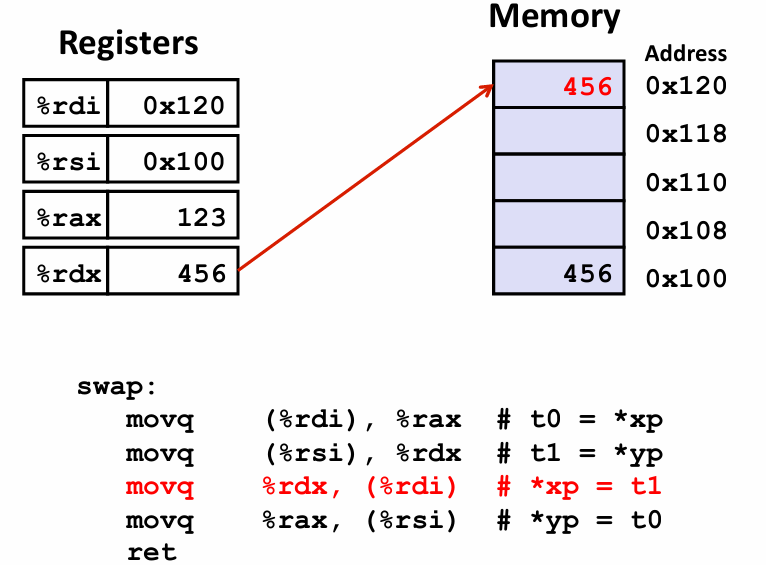
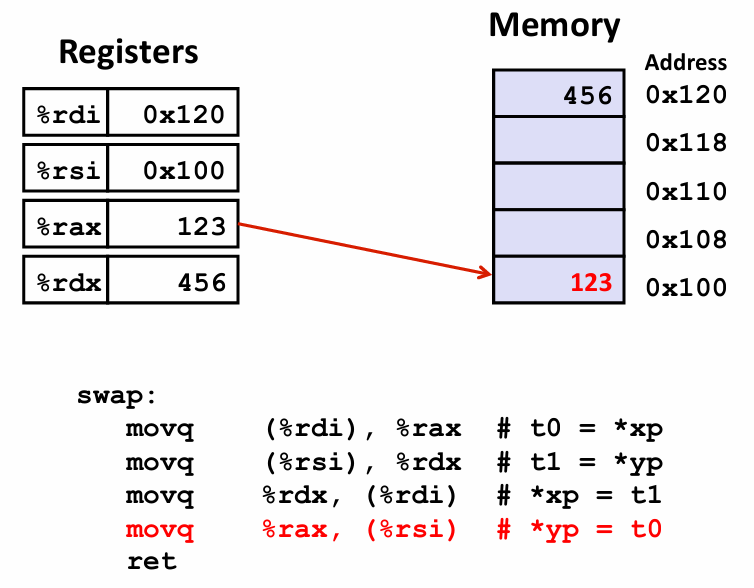
q指的是 quad word 四字 这需要回溯到早期 一个字长是16byte 所以 四字其实指的是64byte
事实上 内存引用()有一个更精细的版本 -- 对实现数组引用很有用
D(Rb,Ri,S)
D - a constant offset 固定偏移量
S - scale factor 比例因子 1,2,4, or 8
Ri - intex register - excect %rsp -- 索引寄存器
Rb - base register -- any of 16 integer registers --基地址
-> Mem[Reg[Rb]+S*Reg[Ri]+D]
其中Reg[Rb] 表示基地址寄存器(base register, Rb)中的值
数组索引 --- 我必须通过字节数 来缩放 索引 换句话说 就是下个索引指向哪 -- int 缩放4倍 long 8倍 这样子

Arithmetic & logical operations
Address Computation
leaq src, dst
基本上是利用C的&符号来计算地址
它看起来像一个有源目的地的mov指令 但是leaq的source必须是address dst是register
实际上做的是地址的运算过程 写入寄存器的是地址值而不是内存值

转换成了计算三倍%rdi的方法
现存三倍的%rdi 然后左移两位 达到12倍的效果
这条指令实际上计算了x + x*2 = 3x,并将结果存储到%rax。在这种情况下,虽然LEA的语法看起来像是在计算地址,但实际上它只是利用了这种形式来快速计算出3x的值。因此,在这里LEA的结果应该被视为一个普通的数值而非地址。
用了上面学的地址运算



有点像 c语言中的 x+=y
order!!!! src在前 des在后

自增 自减 ……
example


???
最终这个lecture我自己整理的文件
![[lecture 05.zip]]